binread: Declarative Rust Binary Parsing
Note: binread has been superceded by binrw (docs.rs link), I'd recommend checking that out instead if you're looking for something to use. It's roughly the same API as binread but with writing support and a lot of other improvements.
Why Rust?
Rust, for those who aren't already aware, is a programming language. The best, in fact (kidding, although it is certainly my favorite). Rust is similar to languages such as C++ due to the fact it is highly efficient, compiles down to machine code, and has no runtime. This makes both languages a great target for everything from operating systems to browsers where you need low-level control to get the best performance possible.
One important feature that sets Rust apart from C++ though for these use cases is its memory safety—without it even a simple mistake in a language like C++ will usually lead to code execution by an experienced attacker (A generalization, but the point is it requires an inhuman level of careful programming to prevent a vulnerability).
(I swear I'm almost at the point) When I'm attacking a system and looking for vulnerabilities, parsers are my go-to for a reason—they often process user-controlled data and they often have memory vulnerabilities. This dangerous combination makes Rust a great tool for doing the job properly. And, better yet, since parsers are rather modular components of programs they can be written in Rust even if the rest of the program is written in, say, C++.
Previous Works
Rust has plenty of work done on parsing, some notable examples:
- nom - a parser/combinator style parsing library. Works for string parsing, bit parsing and byte parsing and has solid performance thanks to being zero-copy. I would highly recommend it.
- byteorder - a great library for providing extensions to Read/Write traits to allow byteorder-configurable parsing (and writing) of integer/float types. A lot of inspiration of binread came from byteorder!
- std - Rust's std now provides
from_be_bytes/from_le_bytes, which can be used somewhat similarly tobyteorder.
(If you know of others, let me know on twitter - @jam1garner)
Design Philosophy
While, admittedly, I can't say I'm quite good enough at thinking out this sort of thing, so don't expect a concise ordered list of values. But the main "benefit" of binread, in my opinion, is that it is declarative. Binary parsing, ultimately, is just defining structure and then applying transformations to convert it into a more usable form. Which begs the question—why are the declarations of structure being done using imperative code?
Let's take a look at an example of what I mean. Here's an example of how different libraries can be used to handle the same (simple) example:
nom:
While this is fast, accurate, and plenty capable/extensible, it... is awfully verbose. Even though we're only defining a simple structure of consecutive primitives this is viciously long to type out and required checking documentation more than I'd like.
Some other criticisms:
- The nature of implementing a parser/combinator system purely using Rust's type system creates an error handling system that is, at least to me, unintuitive.
- nom's dedication to supporting any type of stream (character, byte, bit, etc.) further complicates things
- Just to write the most simple parser, you either have to blindly follow it or have a solid concept of functions that generate closures, which isn't the most beginner friendly.
byteorder:
Similarly, also a bit verbose for my taste. And heavy on the oft-awkward turbofish syntax. And, frankly, writing reader for everything hurts. Extremely redundant, even if I agree with the design decisions that lead to this.
Why declarative?
Now, the point I am making is: imperative/functional-style APIs for parsing will, by nature, be overly verbose. So, I propose a third paradigm: declarative. Here's an example of a (primarily) declarative parsing scheme—010 editor binary templates:
This is all that is needed to parse it—a structure definition. And, optionally, 010 editor supports things like using if statements to gate declarations and other fancy things. But at its core, it is just a struct definition, which we already needed to define for the Rust code anyway (and the parsing code on top of that!). And so, my solution is to use the struct definition as the primary mechanism for writing the parser using a derive macro.
The idea, in action
This is the basics of binread: define a structure and it generates the parser for you. However, this alone only works for fixed-size data composed of primitives. binread takes this concept further by allowing you to use attributes to further control how to parse it.
Some examples of this:
- the
parse_withattribute is an escape hatch of sorts to allow for providing a custom parser function - enums can be used to try multiple parsers until one parses successfully
- the
ifattribute can be used to only parse anOption<T>if a condition (which can involve previously read fields from the same struct!) is true - the
countattribute can be used to provide an expression to decide how many items to read in aVec - the provided
FilePtrwrapper type can be used to read an offset and then read the struct it points to - the
assertattribute allows for providing sanity checks for error handling - and more! see the full list of all the attributes here
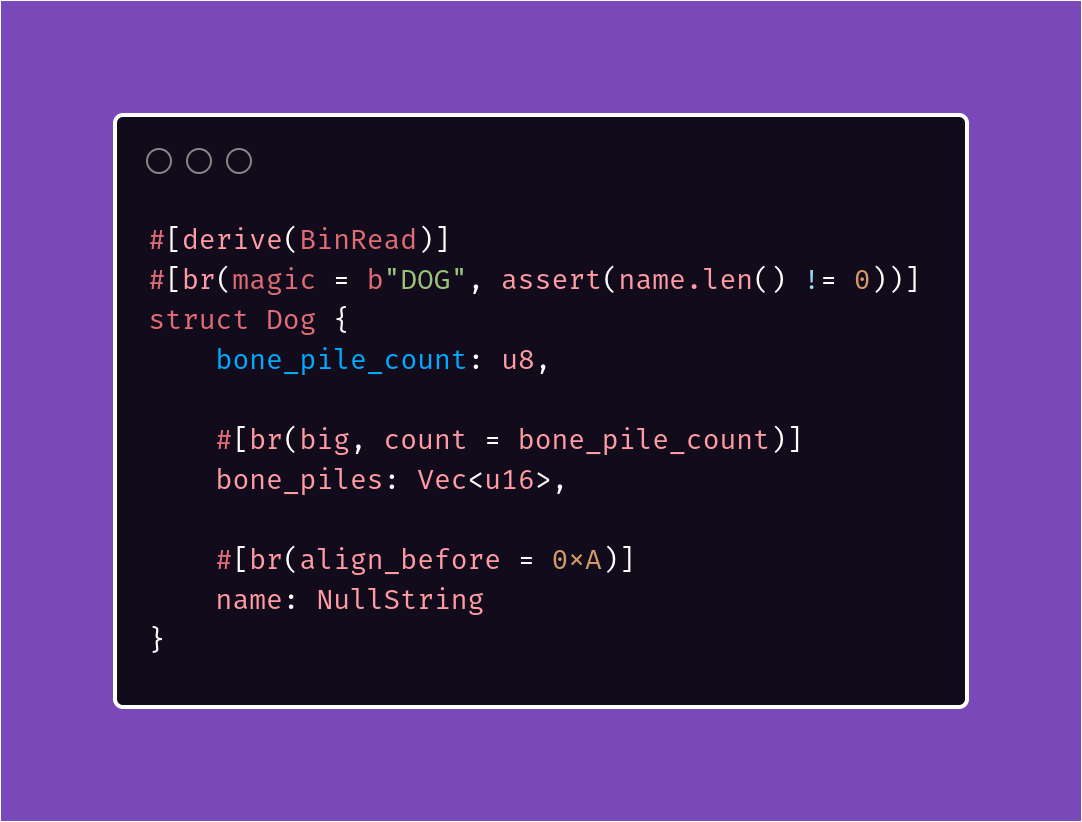
Here's what a more complex binread parser looks like:
List of features:
- no_std compatibility (just disable the
stdfeature) - support for both derive-macro and imperative usage
- parser for all built-in types
- minimal dependencies (proc_macro2, quote, syn, and nothing else)
- support for generating an 010 binary template to help debug parsers in a hex editor with type names and highlighting
- ability to pass data to child structs when parsing
- error handling
- support for structs and enums
- helper types such as
FilePtr,PosValue, andNullString
Want to learn more or try it for yourself? Check out the documentation.
Github: https://github.com/jam1garner/binread (issues/PRs welcome)
Crates.io: http://crates.io/crates/binread