Training a KNN classification model to recognize Trump’s writing style
All the way back in the far off past of 2016, I came across a wonderful analysis by data scientist David Robinson on Trump’s tweets. He was looking into the feasibility of the claim made by VFX specialist Todd Vaziri that every tweet on Donald Trump’s twitter account that was sent from an android was much more hyperbolic than those sent from other devices. If you haven’t read Robinson’s post before I highly suggest you do (and if you enjoy it he also has a followup that is just as good). In case you still are choosing not to read that then (spoilers) he investigates quite thoroughly and finds the claim to be quite accurate.
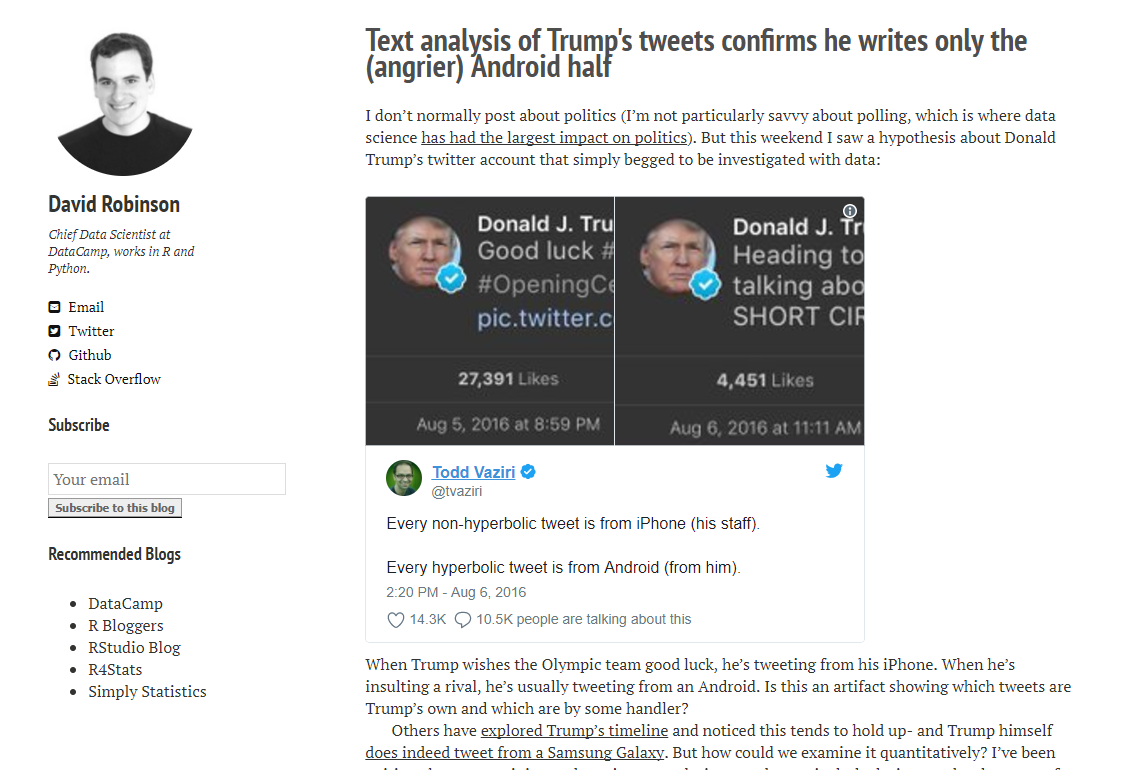
So, as anyone else would do, I got to work on continuing to scroll down my feed and think nothing more of it than an enjoyable read. However more recently, after hearing some cool hubbub about buttons I thought it would be neat to try my own hand at playing with Trump’s tweet data.

My approach is pretty simple. I used a K-nearest nearest neighbors algorithm on a number of factors I picked out in order to try and optimize accuracy. For those who are unaware of what KNN is, here’s a brief summary as it’s simple enough that anyone should be able to get the gist of it. (Go ahead and skip this if you already understand KNN)
KNN Mini Lesson
-----------------
KNN is pretty simple, to train it you give it a bunch of data for it to "learn" from. Then, you give it a test, and it measures the distance between your test point and every one of your training points to find the nearest K (which is an arbitrary number) points. From there you just average out your K nearest neighbors (roll credits) to find the most likely answer. If you want a small example:
Lets say I have 3 plants with the following traits
Type of plant Number of petals Number of leaves
------------- ---------------- ----------------
Lily 6 3
4 leaf clover 0 4
???? 0 3
Now if I use KNN to find out what ???? is using the lily and the 4 leaf clover as training data it will look something like this:
distanceFromLily = squareRoot((6-0)^2 + (3 - 3)^2) = 6
distanceFromClover = squareRoot((0-0)^2 + (4 - 3)^2) = 1
If we use a K of 1 we just get the 4 leaf clover as our most likely candidate (even if ???? only has 3 leaves). If we use a K of 2 however we can actually get prediction percents. Since the lily data point is 6 times further away from ???? than the clover, we know that the KNN predicts it is 6 times more likely to be a clover (1/7th chance for lily, 6/7th chance for clover).
Now the first step is grooming the data to fit the KNN algorithm, in order to do that you need numbers in order to find distances between data points. In order to take something as abstract as a sentence and make it numerical I need to extract features of the tweet. And this is where I tie it back into the data analysis post I mentioned as my inspiration, a couple of feature ideas I blatantly stole from the blog post:
-
Hour of day
-
Whether or not it had a picture/link
-
Whether or not the tweet was in quotes
Other factors I take into account:
-
Exclamation points!
-
ALL CAPS WORDS
-
@mentions
-
#hashtags
-
Notable names (Hillary, Obama)
-
Minimum punctuation distance (Usually equates to sentence length in characters, some are very big others are not. SMALL!)
-
Number of “pauses” this includes… ellipses, commas — even dashes
For my data set, I used a JSON archive for Trump’s 2016 tweets because sadly this pattern no longer exists in 2017 tweets due to him switching over to an iPhone in March of 2017. I run the full archive through my grooming script and it spits out a much smaller groomed JSON file. If you’d like to use it yourself: (It includes newer and older archives) Up-to-date Archive of Trump Tweets
For the actual KNN work thanks to the magic of scikitlearn (originally the magic of individual numpy and scipy) this rather simple algorithm becomes even easier (and faster thanks to not being written in native python for massive array operations).
I separate training and testing into separate functions (as is rather standard). Nothing really out of the ordinary, create a KNN prediction model in the train function and use it in the test function. I split the tweets into training set and test set by every other one, to avoid any bias from trends over time when I load them from the JSON file, then feed the model one half to train and the other half I test and print out whether or not it got them wrong and how sure it was.
Conclusion
So lets take a look at the output.
[https://twitter.com/realDonaldTrump/status/683509528453869569](https://twitter.com/realDonaldTrump/status/683509528453869569) | Probability - 1.000000 | Correct
[https://twitter.com/realDonaldTrump/status/683443848639455232](https://twitter.com/realDonaldTrump/status/683443848639455232) | Probability - 0.800000 | Correct
[https://twitter.com/realDonaldTrump/status/683394224184758272](https://twitter.com/realDonaldTrump/status/683394224184758272) | Probability - 0.800000 | Correct
[https://twitter.com/realDonaldTrump/status/683378470093746176](https://twitter.com/realDonaldTrump/status/683378470093746176) | Probability - 0.500000 | Wrong
[https://twitter.com/realDonaldTrump/status/683277309969694720](https://twitter.com/realDonaldTrump/status/683277309969694720) | Probability - 1.000000 | Correct
[https://twitter.com/realDonaldTrump/status/683259029804695552](https://twitter.com/realDonaldTrump/status/683259029804695552) | Probability - 0.900000 | Correct
[https://twitter.com/realDonaldTrump/status/683128636279361537](https://twitter.com/realDonaldTrump/status/683128636279361537) | Probability - 1.000000 | Correct
[https://twitter.com/realDonaldTrump/status/683070410993364992](https://twitter.com/realDonaldTrump/status/683070410993364992) | Probability - 0.800000 | Correct
[https://twitter.com/realDonaldTrump/status/683066224251645953](https://twitter.com/realDonaldTrump/status/683066224251645953) | Probability - 1.000000 | Wrong
[https://twitter.com/realDonaldTrump/status/683062220490715136](https://twitter.com/realDonaldTrump/status/683062220490715136) | Probability - 0.800000 | Correct
[https://twitter.com/realDonaldTrump/status/683060654098530305](https://twitter.com/realDonaldTrump/status/683060654098530305) | Probability - 0.500000 | Wrong
[https://twitter.com/realDonaldTrump/status/683037464504745985](https://twitter.com/realDonaldTrump/status/683037464504745985) | Probability - 0.900000 | Correct
[https://twitter.com/realDonaldTrump/status/682805320217980929](https://twitter.com/realDonaldTrump/status/682805320217980929) | Probability - 1.000000 | Correct
[https://twitter.com/realDonaldTrump/status/682764544402440192](https://twitter.com/realDonaldTrump/status/682764544402440192) | Probability - 1.000000 | Correct
Percent Correct - 83.14393939393939
An accuracy of 83% isn’t too bad, if we were doing completely random guessing we’d have 50% accuracy (is Trump vs isn’t Trump). However if we delve deeper we notice that a lot of the ones that are missed are ones sent from iPhone. If we take a look at some of those however…
|
|
|
All 3 of these are very clearly written in Trump’s signature style, and to no surprise these are 3 of the “wrong” iPhone tweets with the highest odds of being from Trump according to the KNN model. This small bit of evidence, albeit anecdotal, goes to show that it would work quite well at predicting whether or not tweets outside of 2016 were sent by him. Who knows, maybe there’s just a slight chance Trump himself was the one who tweeted out about how big his button is?
Questions? Comments? Concerns? Suggestions? Want More? I’m on twitter.
Enjoyed it? Please consider clapping, sharing, following, or commenting to indicate to me you want more like this.
Want to check out the code yourself? It’s on github: https://github.com/jam1garner/did-trump-tweet-it