Thoughts on Context and Capabilities in Rust
Earlier today I read through Tyler Mandry's Context and Capabilities in Rust and I really liked what I saw. But I, like many, had lots of questions. How would this effect the language? Would this harm locality/readability? What is needed to make this fit well?
So here's an exploration of my thoughts so far.
Temporal Trait Implementation
One concept Tyler explored throughout the post was the idea of traits which are implemented only for a given lifetime. But this raises a question: how do we constrain these lifetimes when specifying implementation?
This is actually a question he delved into in his own post concerning how it would be possible to send a context variable across threads:
fn deserialize_and_print_later<T>(deserializer: &mut Deserializer)
where with('static + Send) T: Deserialize + Debug
{
std::thread::spawn(|| {
// ...
});
}
The syntax here representing that all of T's context must live for 'static and must be able to be sent across threads. This is a tricky thing to handle because now generic code that has liveliness, thread-safety, or other requirements would now need to specify this requirement. Except that's a backwards compatibility issue!
One solution would be to simply disallow context-dependent trait implementations until the function opts-in (for example, by doing with('_) to opt-in without specifying any constraints on the context variables). This is obviously not ideal, as this does a lot of damage to one of the primary usecases (smuggling context variables through code that doesn't currently allow for it but is generic). But this could be inverted in future editions, where with('_) is the default behavior, and using a potentially context-ridden generic requires specifying any bounds the context.
My initial impression of this while talking with tmandry made me worried this wouldn't be possible without introducing a lot of boilerplate. But then I considered the amount of long-living generics I deal with day-to-day and realized this wouldn't require much changes due to the fact that if any instance of a generic type is involved, this shouldn't actually be an issue. For example, if I have a Vec<T>, defining insert would not involve me specifying a minimum lifetime of the context.1
Moves, References, Mutability, Drop and Copy
Another concern to consider is that since a context variable is ultimately just that, a variable, it has to deal with the complexities of Rust's ownership system. So let's explore how easily it handles that. (Note: I'm going to continue using the syntax introduced by tmandry for clarity/consistency, but ultimately I think capability is a poor choice for declaring the binding, and I personally prefer context)
capability my_num = i32;
fn print_num()
with my_num,
{
println!("my_num + 1 is: {}", my_num + 1);
}
fn main() {
with my_num = 3 {
print_num();
print_num();
print_num();
}
}
Just to get it out of the way: Copy types. These are dealt with trivially, since they have no real ownership requirements involved. Fortunately, with Drop, there also isn't much special about it. The only really interesting case is nested with blocks (with each more local with overriding the previous with)—however for that it's the same as variable shadowing, so no variable involved is being dropped any earlier anyhow.
How about if we introduce mutability? At face value this feels like a pretty bad idea: after all this is somewhat like a mix between a global variable and a parameter when it comes to ergonomics, but let's see where it takes us.
capability mut my_num = i32;
fn inc_num()
with mut my_num,
{
my_num += 1;
}
fn main() {
with mut my_num = 0 {
inc_num();
inc_num();
println!("{}", my_num);
}
}
This poses an interesting question: what is my_num within the bounds of inc_num? What does assignment to it even mean? My instinct tells me that it's closer to a captured variable in a closure: either you move it or you borrow it. So in this case logically this should be functionally a reference, as we aren't moving out of it. But, like closures, we are "capturing" my_num, so we don't actually need to treat it as a reference when assigning to it:
let mut x = 0;
let mut y = || {
// no dereference needed
x += 1;
if x == 3 {
println!("3!");
}
};
y();
y();
y();
y();
println!("{}", x);
Now, thinking about this in the lense of that, it can be understood that the binding being used like this is a reference. This also logically introduces the idea of being able to move out of a context variable:
capability my_name = String;
fn get_name() -> String
with move my_name,
{
my_name
}
fn main() {
with mut my_name = String::from("Alice") {
let name = get_name();
let name2 = get_name(); // ERROR: cannot move out of my_name twice
}
}
This comparison to closures works quite nicely, however unlike closures, the capturing of state isn't done at definition (construction, in the case of closures), it's done when the call happens. Meaning it doesn't take mutable aliasing to have multiple functions "capture" the same state mutably. For example:
capability x = i32;
fn add_1()
with mut x,
{
x += 1;
}
fn add_2()
with mut x,
{
x += 2;
}
fn main() {
with mut x = 0 {
add_1();
add_2();
add_1();
}
}
If we try to do the same with closures:
let mut x = 0;
let add_1 = || {
x += 1;
};
let add_2 = || {
// ^^ ERROR: cannot borrow `x` as mutable more than once at a time
x += 2;
};
add_1();
add_2();
add_1();
That's because when the closure desugars, it looks something like:
struct Closure_add_1<'a> {
x: &'a mut i32,
}
impl<'a> Fn() for Closure_add_1<'a> {
fn call(&mut self) {
*self.x += 1;
}
}
// ...
let add_1 = Closure_add_1 { x: &mut x};
let add_2 = Closure_add_2 { x: &mut x}; // <--- second mutable reference not allowed since `add_1`'s reference gets used on the next line and is thus still lively.
add_1.call();
add_2.call();
add_1.call();
While the context-based version would desugar to something like:
fn add_1(x: &mut i32) {
*x += 1;
}
// ...
let mut x = 0;
add_1(&mut x);
add_2(&mut x);
add_1(&mut x);
So the mutable reference begins and ends with the given call. Because, like function call parameters, the default lifetime of the context is '_, so specifying it would look something like:
fn return_ref_to_context<'a>() -> &'a mut i32
with mut my_num: 'a,
{
&mut my_num
}
Why?
Good question. The second I saw this proposal, it was clear this was the closest thing to a solution to 3 major items on my Rust wishlist. And it might not be super clear how I've managed to find 3 entirely unique (and somehow important) features out of the simple idea of implicit(ish) argument passing. So let's cover them!
Function Coloring
If you're familiar with async programming discourse™ you'll have heard the term "function color" before. Honestly, most of the discussion around it is really boring (and usually a bit obnoxious). Primarily, the term "function coloring" is used negatively2. The gist of the argument is: "Rust's async paints certain functions red (sync) and certain functions blue (async) and you can't mix them and that's bad". It's not necessarily a bad argument—library authors, for example, experience poor ergonomics when supporting both async and sync paradigms. Regardless of whether or not you agree with "function color" being a bad thing (or even being a thing that applies to Rust's async), it's hard to argue against it being a useful concept in the context of Rust. Rust intends to be usable on deeply embedded systems and that limits its ability to do "colorless" functions in the traditional manner (which often has a level of runtime that traditionally has not been considered acceptable in Rust).
However, I think in the general case, it's a useful construct to be able to color functions. The ability to statically prove that a function fits into a certain category is useful, the same way that statically proving that a type fits into a certain category (generic constraints) is useful. However currently Rust has no way to handle this. Types have this property by means of traits: if you want to prove a type can do a certain task, it implements a trait with methods to perform that task. If you want to prove a type has a certain characteristic, than you have marker traits in order to indicate a property. Copy types can be trivially copied. Sync types can be shared across threads. Send types can be sent across threads. These are useful properties to assert, as they allow you to ensure correctness of your program by means of allowing the compiler to verify them for you every compile.
Capabilities would have a similar dichotemy but for functions. For example, tmandry's blog post covers the equivelant to non-marker traits: context variables which are actually used for passing data. However one thing his blog post doesn't go into is the fact that you could also have context variables without data in order to assert various propeties.
For example, what if we used this property to "color" multithreaded code so that we could statically assert our code is single threaded:
trait AllowStdThreads {}
capability threading;
struct MultiThreaded;
struct SingleThreaded;
impl AllowStdThreads for MultiThreaded {}
fn spawn_thread<F>(func: F)
with threading: AllowStdThreads,
where F: Fn() + Send + Sync + 'static,
{
std::thread::spawn(func);
}
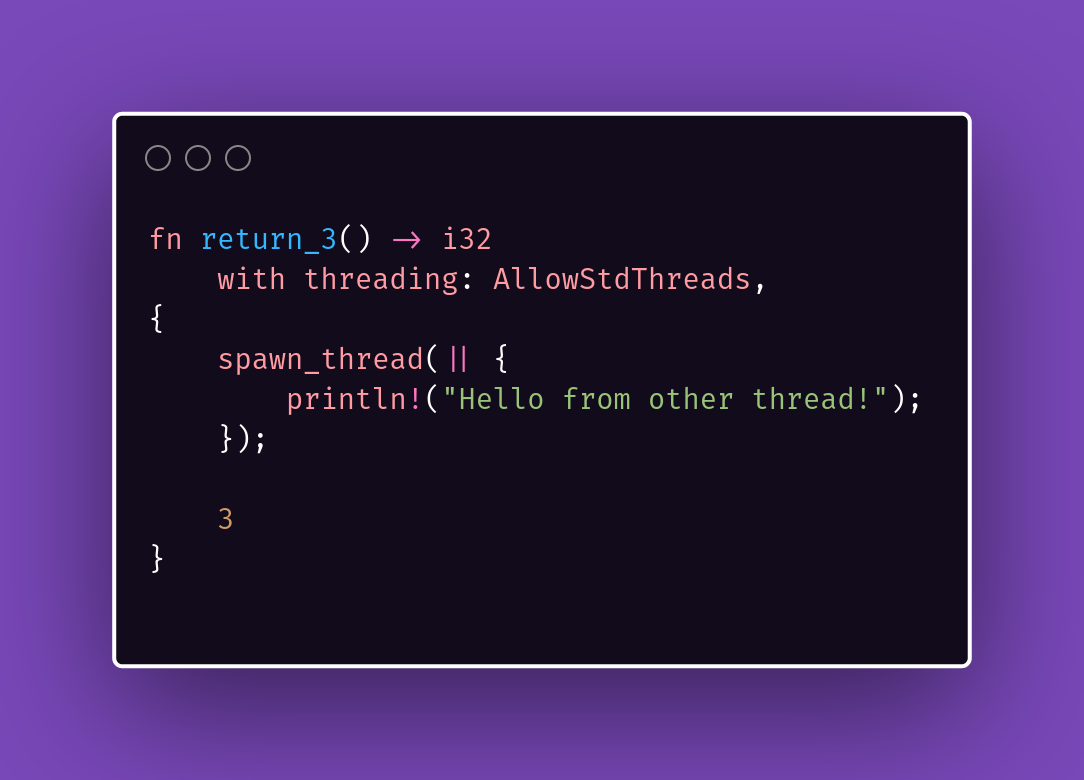
fn return_3() -> i32
with threading: AllowStdThreads,
{
spawn_thread(|| {
println!("Hello from other thread!");
});
3
}
fn main() {
with threading = SingleThreaded {
let random_num = return_3();
// ^^^^^^^^^^
// ERROR: `SingleThreaded` does not implement `AllowStdThreads`
println!("Random number: {}", random_num);
}
}
This also has the benefit of (when appropriate) showing in the function signature of return_3 info about what the specific function requires in order to operate. It's like #![no_std], but with more granularity and room for domain-specific function coloring as needed.
This is not an everyday need by any means, but it's really useful when you need it. However it's worth noting that, like unsafe, by default this can be encapsulated such that return_3 could simply include its own with block, rather than bubble up the requirement. I'll note that it's similarly possible to forbid encapsulating it, however that is beyond the scope of this blog post. I do, however, think this is a really useful property, especially when combined with other API tricks (for example sealed traits).
Smarter Pointers (and API growth)
One issue that makes Traits and callbacks annoyingly rigid when it comes to forwards compatibilities is that they often have to choose between forwards-compatibility (pass a user-defined generic context variable for any user-defined data) and simplicity (not do that, because it kinda sucks). And sometimes you don't even have this foresight. Sometimes you're not even the library author. And so you suffer, having no way to pass your data to the implementation you made yourself.
The epitome of this woe, to me, is Deref. Oh Deref. My beloved. My dear. How you twist the knife every time I attempt to (ab)use you for things too-good-to-be-true. Your harrowing fn deref(&self) -> &Self::Target; brings my heart nothing but sadness.
The gist of the matter is: a good while back I wanted to make a declarative zero-copy parsing library. The idea was simple: fread (from libc) is surprisingly good at binary parsing. I mean it's not amazing, but for a C API it's quite ergonomic. You declare your structs in the layout they're defined in the format you're parsing, then you pass a pointer to fread and it just reads the bytes directly into the struct. It's simplicistic, it's easy to use, it's almost nice. There's really only one core issue, the whole "not at all type safe or memory safe or really anything safe" part. But that's such a small detail, I'm sure it can be worked around.
So let's take a look at the API I wanted to have (at least for my prototype, please understand that this is gross. if you care about the more refined design with none of the mess, see binrw):
#[repr(C)]
struct Header {
size: u32,
version: u32,
body: FilePtr64<Body>,
}
#[repr(C)]
struct Body {
field1: u32,
field2: f32,
field3: u64,
}
let my_file = parse::<Header>("myfile.bin").unwrap();
println!("body.field2: {}", my_file.body.field2);
The idea was that the parse function would memmap the file, then cast the start of the file to a pointer to Header, then give you a File<Header>, which could then Deref to &Header. And that worked great (minus not being a very Rust way to do things), but then came the problem of accessing the body field. FilePtr64<T> was a smart pointer (i.e. it Deref'd to &T), but it require thread-local variables in order to work, as Deref takes no arguments, and the actual storage of FilePtr64 had to be only the u64 read from the file (as otherwise the layout wouldn't match the file).
Ignoring the terrible implications of that library design, sometimes you just don't have a channel to pass your user data through without some form of global/thread-local. That's decently common with traits (ever notice how every web framework let's you pass a context variable?), and I find it especially annoying when I want to use Display or another standard trait, but have no means of passing data to my implementation.
And the thing is, built-in capability/context variable support would allow this forward-compatible API growth without any intervention by the author of the trait/library. This isn't just a trick to allow std maintainers to add an opt-in field to a trait they couldn't see the future about, this is a feature that would allow anyone to be afforded the flexibility they need without author intervention.
API Consumer-Defined Globals
One complaint I hear pretty often about the Rust standard library is that it gets to use all these fancy features nobody else does. Do I think the standard library should be stable-only? Absolutely not, but I do often feel the same jealousy of rustc's nice juicy features that I want in my own codebase.
One such example is the global allocator API. The global allocator API, for those who aren't familiar, goes something like this: the Rust standard library comes with its own allocator, but for a lot of people they want to substitute in their own allocator. wasm needs low code footprint, games need allocation speed at all costs, kernels need to use their own kernel allocator API, and I'm sure there's some Windows usecase that needs an allocator I've never heard of before.
The point is, an allocator is a global resource that an end-user (e.g. application programmer, not application user) often will want to set to their own value. And it looks something like this:
#[global_allocator]
static ALLOC: wee_alloc::WeeAlloc = wee_alloc::WeeAlloc::INIT;
You make a static variable, you set it to your allocator, and then you use this magic attribute that sets it as your global allocator.
But why should that be a language feature? There's not anything special about allocation that requires Rust be the arbiter of it all. Ideally, any crate should be able to say "hey I need you to create a global variable that implements this trait"3 (and optionally provide a default like the standard library does).
For example, this would be extremely useful for logging! Passing a trait object to some logger::install function is kinda gross, and not really zero-cost. It also kinda sucks for if I want to override a logger for a given scope.
Enough complaining, here's my proposal:
// === log crate ===
trait Logger { /* ... */ }
capability logger: Logger;
with logger: StubbedLogger = StubbedLogger::new();
// === my_web_server crate ===
use log::logger;
use stdout_logger::StdOutLogger;
use env_logger::EnvFileLogger;
with logger = StdOutLogger;
fn main() {
// logs to stdout
log::info!("Starting up file logger...");
// logs to file
with logger = EnvFileLogger::new() {
// business logic
}
}
This would allow contextual overriding, remove need for heap allocation (if the logger itself needs to hold a buffer or something similar), and allow for statically-verified scoped overrides. This would be fantastic for things like being able to take code that uses the global alloactor and using, say, an arena allocator, if it gives you performance gains. All without needing the ability to modify the code using the global allocator. And (in theory) this change would be backwards compatible, as std::alloc::System would simply need to add a with clause to its GlobalAlloc implementation.
Conclusion
This feature proposal, while far from the easiest feature to implement, has me genuinely excited by the possibility. I hope there is continued interest in this area of design, as I think it has a lot of potential with regards to enabling some APIs that would not be possible (or in some cases just significantly less ergonomic).
There's a lot of little bits and details that need ironing out (trait objects, function pointers, syntax, backwards compatibility concerns, specification of trait implementation lifetimes, etc etc etc)
But I'm excited to see if anything comes of this. I really think it elegantly strings a lot of my problems with the language into a single issue and then solves it.
Thanks to Evan Richter, Raytwo, and David Golembiowski for reviewing this blog post before release <3
-
Since the variance of the lifetime with respect to our generic parameter
Tis covariant, we can ensure the context is lively due to the fact that the context must exist forTup until the last function call in which the context variable is marked as a requirement of ↩ -
"What Color is Your Function?", "Why async Rust doesn't work", Rust's Async isn't fucking colored, "Rust async is colored, and that's not a big deal" ↩
-
I've actually discussed a similar proposal with @yoshuawuyts (one of the people involved with tmandry's proposal!) ↩